Christophe Crespelle and Fabien Tarissan
in Complex Networks, special issue of Computer Communications, 34-5, pp. 635-648 (2011), DOI: 10.1016/j.comcom.2010.06.006
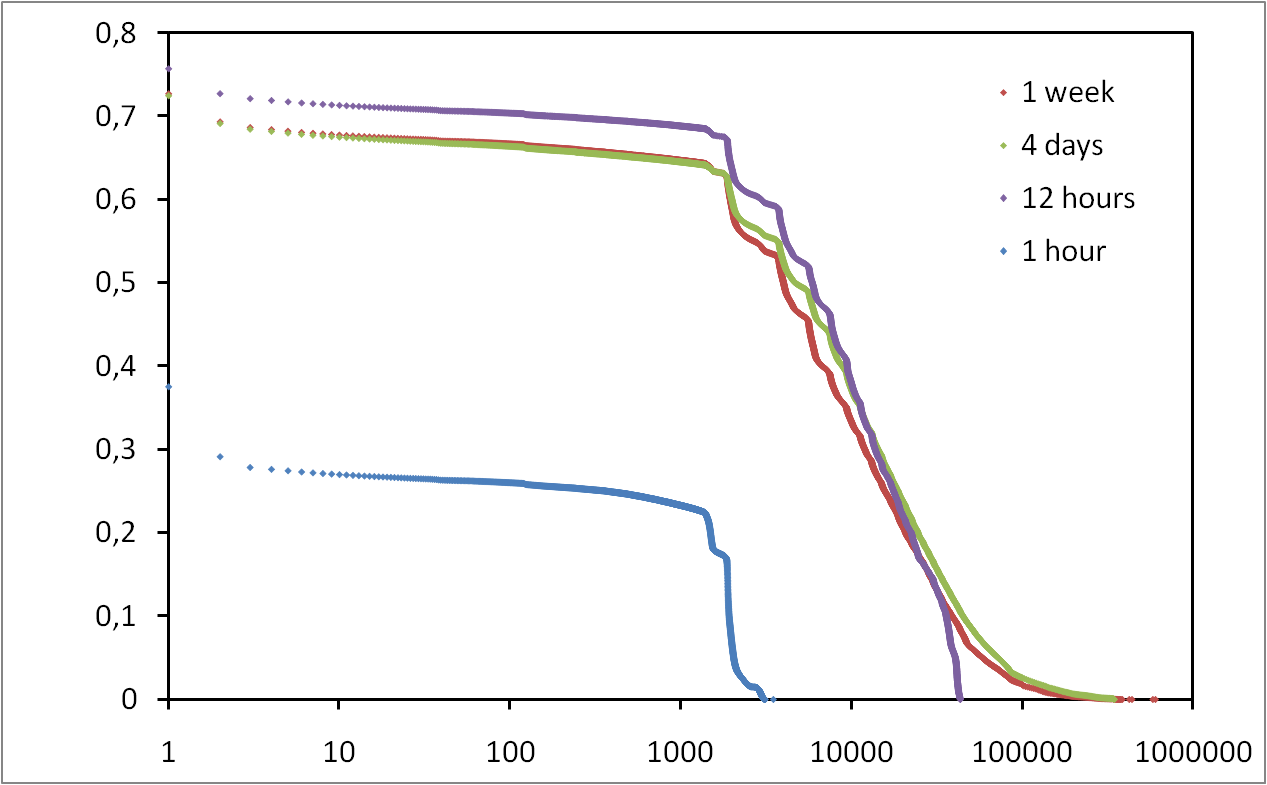
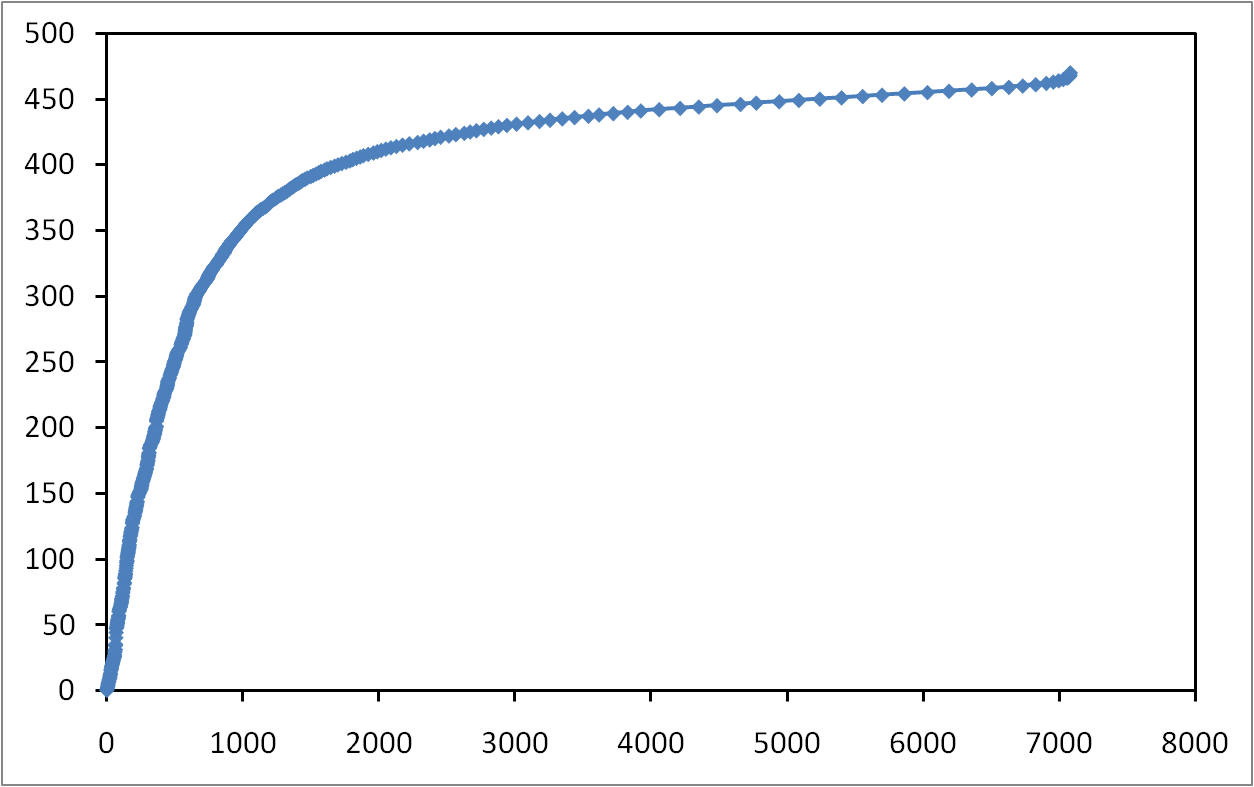
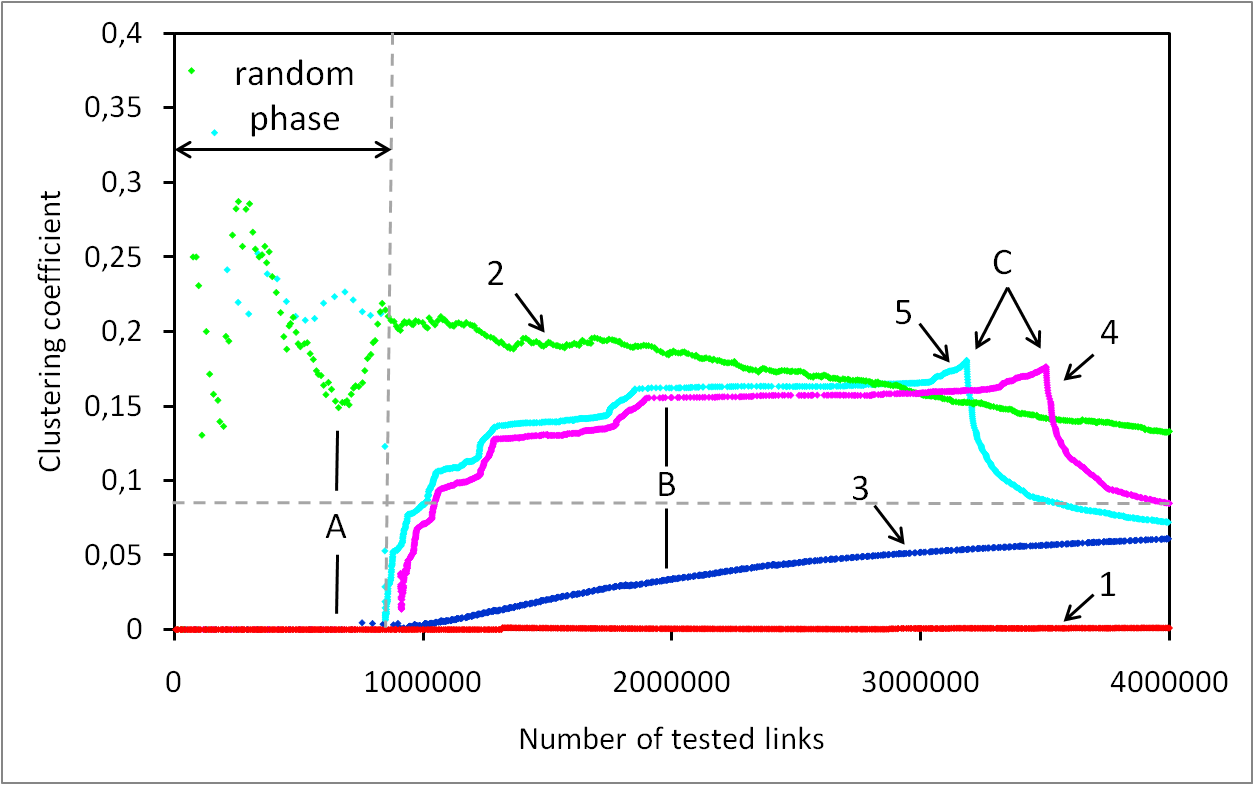
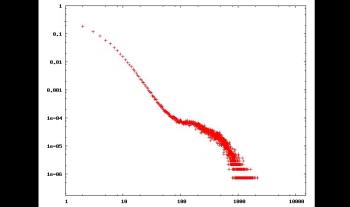
Many contributions rely on the degree distribution of the Internet topology. However, current knowledge of this property is based on biased and erroneous measurements and is subject to much debate. Recently, a new approach, referred to as the Neighborhood Flooding method, was proposed to avoid issues raised by classical measurements. It aims at measuring the neighborhood of Internet core routers by sending traceroute probes from many monitors distributed in the Internet towards a given target router. In this paper, we investigate the accuracy of this method with simulations. Our results show that Neighborhood Flooding is free from the bias highlighted in the classical approach and is able to observe properly the exact degree of a vast majority of nodes in the core of the network. We show how the quality of the estimation depends on the number of monitors used and we carefully examine the influence of parameters of the simulations on our results. We also point out some limitations of the Neighborhood Flooding method and discuss their impact on the observed distribution.